گروه سیستمهای اطلاعات و علوم داده
محورهای پژوهشی: پژوهشهای بنیادی
بهینهسازی از عناصر محوری در تحقق بسیاری از دستاوردهای هیجانانگیزی است که در زمینههای مختلف علوم داده نظیر یادگیری ماشین، پردازش زبان، هوش مصنوعی و پردازش سیگنال حاصل شده است. روند روزافزون افزایش پیچیدگی مدلهای مورد بررسی در علوم داده و متناظر افزایش حجم دادگان، نیاز به روشها و الگوریتمهایی کارا، قابل اتکا و قابل اثبات بیش از گذشته حس میشود. در این راستا بهرهگیری از مفاهیم و روشهای گوناگون حوزه محاسبات، بهینهسازی و پردازش نقش مهمی ایفا خواهد نمود. به طور مثال، بهینهسازی در برنامهریزی خطوط هوایی، امور مالی، طراحی مهندسی و سیستمهای زیستی نقش پررنگی دارد. در همه این مسائل سعی میکنیم پارامتر یا پارامترهایی را تحت مجموعهای از قیود بهینه کنیم؛ مثلا حداکثر کردن سود و کارایی یا حداقل کردن هزینه و مصرف انرژی. منابع و زمان همیشه محدود هستند و این اهمیت بهینهسازی را بیشتر میکند.
پیشرفتهای چشمگیر اخیر در حوزه علوم داده و محاسبات در حوزه بهینهسازی نیز تأثیرگذار بوده است. امروزه مسائل صنعتی مهمی در ابعاد کلان به کمک بهینهسازی بررسی میگردند که در ده سال گذشته حل آن قابل تصور نبود. روشها و الگوریتمهای نوآورانه در حوزه بهینهسازی در کنار پیشرفتهای صورت پذیرفته در بستر فناوری و منابع محاسباتی نقش پررنگی در تحقق پیشرفتهایی چشمگیر در علوم داده ایفا نموده است.
تحقیقات در گروه علوم داده شریف شامل مسائل نظری و عملی بهینهسازی گسسته و پیوسته در مقیاس کلان میشود. بهینهسازی تصادفی، بهینهسازی مقاوم، بهینهسازی ترکیبیاتی و بهینهسازی محدب و نامحدب از جمله عناوین تحقیقاتی گروه در این مبحث است.
پیشرفتهای چشمگیر اخیر در حوزه علوم داده و محاسبات در حوزه بهینهسازی نیز تأثیرگذار بوده است. امروزه مسائل صنعتی مهمی در ابعاد کلان به کمک بهینهسازی بررسی میگردند که در ده سال گذشته حل آن قابل تصور نبود. روشها و الگوریتمهای نوآورانه در حوزه بهینهسازی در کنار پیشرفتهای صورت پذیرفته در بستر فناوری و منابع محاسباتی نقش پررنگی در تحقق پیشرفتهایی چشمگیر در علوم داده ایفا نموده است.
تحقیقات در گروه علوم داده شریف شامل مسائل نظری و عملی بهینهسازی گسسته و پیوسته در مقیاس کلان میشود. بهینهسازی تصادفی، بهینهسازی مقاوم، بهینهسازی ترکیبیاتی و بهینهسازی محدب و نامحدب از جمله عناوین تحقیقاتی گروه در این مبحث است.
در کنار موارد فوق، حوزه پردازش کوانتومی هم در سالهای اخیر به طور جدی در سطح جهانی مطرح گردیده و شرکتهایی همچون گوگل و مایکروسافت در این زمینه سرمایهگذاری عمدهای داشتهاند. گروه علوم داده شریف هم به این حوزه توجه خاصی داشته و با همکاری گروه کوانتومی پژوهشکده همگرا در این زمینه نیز به فعالیت خواهیم پرداخت. در شکل زیر نمایی از برخی فعالیتهای میان رشتهای در این حوزه دیده میشود.
بهینهسازی مقاوم و تصادفی
در طیف وسیعی از مسائل بهینهسازی که با دنیای واقعی مواجهاند، چالش عدم قطعیت وجود دارد و یک یا چند متغیر مسئله رفتاری تصادفی دارند. چالشی که در این حالت به وجود میآید، حجیم بودن فضای احتمالی است که میتواند حل مسأله را دشوار نماید. بهینهسازی تصادفی و مقاوم به عنوان روشهایی عدم قطعیت-آگاه (uncertainty-aware) در چند دهه گذشته به ابزارهایی ضروری در زمینههای مختلف مهندسی، علم اقتصاد، علوم کامپیوتر و آمار بدل شدهاند.
بهینهسازی ترکیبیاتی
بسیاری از برنامه های کاربردی دنیای واقعی به طور طبیعی به عنوان مسائل بهینهسازی ترکیبیاتی فرموله میشوند، به عبارت دیگر مسائل یافتن بهترین راهحل(ها) از یک مجموعه محدود. روشهای مختلفی برای مقابله با چنین مشکلاتی توسعه یافتهاند: برنامهریزی عدد صحیح، الگوریتمهای قابل حمل و دقیق با پارامتر ثابت، الگوریتمهای تقریب و الگوریتمهای ترکیباتی. این روشها را میتوان برای مسائل مختلف از حوزههای مختلف، از بیوانفورماتیک گرفته تا هندسه، تا برنامهریزی و چندین مورد دیگر به کار برد.
بهینهسازی محدب و نامحدب در یادگیری ماشین و شبکههای عصبی (و شبکههای عمیق)
در بهینهسازی محدب تابع هدف تنها یک نقطه بهینه دارد، و همان تابع بیشینه یا کمینه سراسری تابع است. درحالی که وقتی با شبکههای عصبی سر و کار داریم، توابع تعداد زیادی نقطه بهینه محلی دارند و مشخص کردن بهینه سراسری یا حتی یک بهینه محلی مناسب کار سختی میشود. باتوجه به اهمیت روزافزون شبکههای عصبی در مسائل مختلف، بهینهسازی نامحدب هم بسیار کاربردی شده است. در این حوزه راهکارهای مختلف برای کمک به یادگیری شبکه عصبی بررسی میشوند. برای مثال نرخ یادگیری مناسب و روشهای مختلف برای فرار از نقاط بهینه محلی میتوانند به حل این مشکل کمک کنند. (منبع)
امروزه تقریبا هیچ صنعت مهمی وجود ندارد که هوش مصنوعی روی آن اثر نگذاشته باشد. تشخیص سرطان و بیماریها، پیشبینی آب و هوا، ماشینهای خودران و دستیار صوتی تنها بخشی از کاربردهای روزافزون این حوزه هستند.
هوش مصنوعی هسته اصلی یادگیری ماشین است؛ رایانهها به کمک آن مقادیر کلان داده را پردازش کرده و از نتایج آن برای گرفتن تصمیمهای بهینه استفاده میکنند. روشهای مبتنی بر یادگیری عمیق به همراه داده کلان روز به روز در مسائل مختلف کاربرد پیدا میکنند. پیشرفت تکنولوژی جمع آوری و پردازش داده در سالهای اخیر هم موجب شده که توجه به این حوزه افزایش پیدا کند.
گروه علوم داده شریف بطور زیربنایی بر روی مبانی یادگیری ماشین و سیستمهای تصمیمگیری متمرکز است. تحقیقات گروه عناوین مختلف نظری و عملی از این حوزه را پوشش میدهد. نظریه یادگیری ماشین، بهینهسازی، یادگیری و استنباط آماری و الگوریتمهای هوش مصنوعی در کنار یادگیری عمیق، یادگیری تقویتی، بینایی کامپیوتر و پردازش زبان طبیعی از سرفصلهای این بخش میباشد.
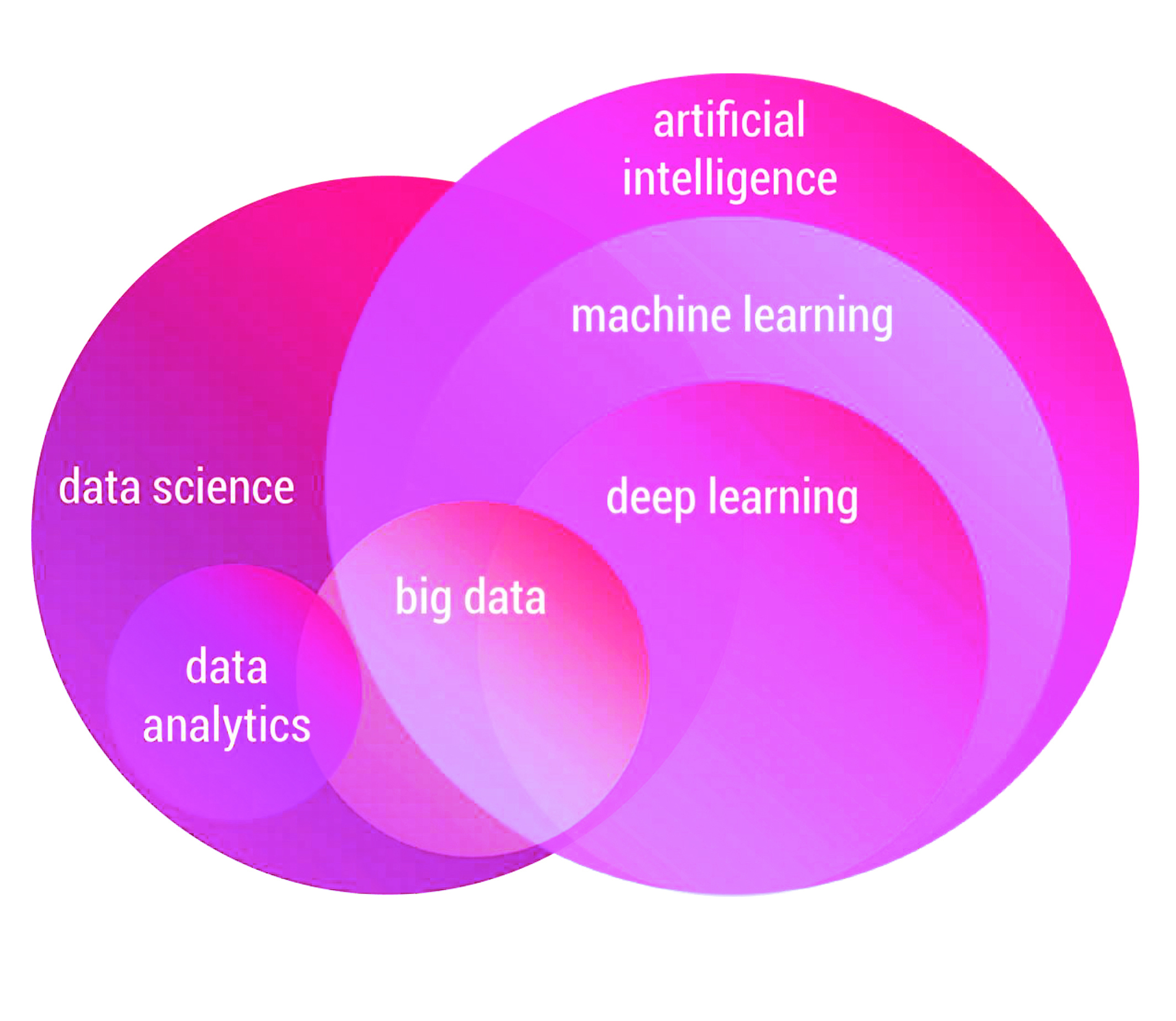
هوش مصنوعی هسته اصلی یادگیری ماشین است؛ رایانهها به کمک آن مقادیر کلان داده را پردازش کرده و از نتایج آن برای گرفتن تصمیمهای بهینه استفاده میکنند. روشهای مبتنی بر یادگیری عمیق به همراه داده کلان روز به روز در مسائل مختلف کاربرد پیدا میکنند. پیشرفت تکنولوژی جمع آوری و پردازش داده در سالهای اخیر هم موجب شده که توجه به این حوزه افزایش پیدا کند.
گروه علوم داده شریف بطور زیربنایی بر روی مبانی یادگیری ماشین و سیستمهای تصمیمگیری متمرکز است. تحقیقات گروه عناوین مختلف نظری و عملی از این حوزه را پوشش میدهد. نظریه یادگیری ماشین، بهینهسازی، یادگیری و استنباط آماری و الگوریتمهای هوش مصنوعی در کنار یادگیری عمیق، یادگیری تقویتی، بینایی کامپیوتر و پردازش زبان طبیعی از سرفصلهای این بخش میباشد.
یادگیری عمیق
یادگیری عمیق از روشهای یادگیری ماشین مبتنی بر شبکههای عصبی است. این شبکهها امکان یادگیری از مقادیر حجیم داده را فراهم میکنند. روشهای یادگیری عمیق با تنوع ساختاری و زیاد کردن تعداد لایههای شبکههای عصبی، در مسائل مختلف به دقتهای بسیار بالایی رسیده است.
یادگیری تقویتی
یادگیری تقویتی یکی دیگر از روشهای یادگیری ماشین است که در آن یک عامل میآموزد چگونه در محیط با انجام اقدامات و دیدن نتایج آنها رفتار کند. عامل در یک محیط تعاملی با آزمون و خطا و بازخورد اقداماتش آموزش میبیند. از یادگیری تقویتی بصورت سنتی در بازیهای کامپیوتری و روباتیک استفاده میگردیده ولی در سالهای اخیر حوزههای گستردهای از یادگیری ماشین را فراگرفته است.

پردازش زبان طبیعی
پردازش زبان طبیعی به عملیات درک زبان انسانها توسط ماشین گفته میشود. زبان میتواند گفتاری یا نوشتاری باشد، و ماشین باید آن را تشخیص، درک و تولید کند. پردازش زبان طبیعی ریشه در زبان شناسی دارد، اما در اواخر قرن بیستم، با معرفی روشهای آماری و افزایش توان محاسباتی پردازندهها، انقلابی در این حوزه به وجود آمد و تبدیل به یکی از شاخههای مهم هوش مصنوعی شد. در ادامه روشهای یادگیری ماشین و شبکه عصبی به دلیل دقت بالا در پردازش زبان طبیعی متداول شدند و به نتایجی مشابه انسان رسیدند. امروزه ردپای پردازش زبان طبیعی در دستیارهای صوتی، چتباتها، تصحیح گرامر، ترجمه ماشینی، دستهبندی و خلاصهسازی متون، تحلیل احساسات و حتی معاملات اقتصادی به چشم میخورد.
بینایی کامپیوتر
بینایی کامپیوتر حوزهای از هوش مصنوعی است که روی استخراج اطلاعات از تصاویر دیجیتال و فیلمها تمرکز میکند. ماشین با توجه به این اطلاعات میتواند تصمیم بگیرد یا ما را راهنمایی کند. یک سیستم آموزش دیده برای بازرسی محصولات میتواند هزاران محصول را در دقیقه تحلیل کند، که بسیار از انسان سریعتر است. بینایی کامپیوتر در صنایع مختلف از انرژی و آب و برق گرفته تا تولید خودرو استفاده میشود. دستهبندی تصاویر، تشخیص اشیاء، ردیابی اشیاء و بازیابی تصاویر مبتنی بر محتوا از مسائل مهم این حوزه است.

پیشرفتهای اخیر در زمینه توسعه الگوریتمهای بهینه با قابلیت پیادهسازی عملی مرهون همافزایی ایدههایی خلاقانه در حوزه نظریه اطلاعات، نظریه یادگیری، آمار، احتمال و تئوری علوم کامپیوتر است که منجر به تدوین طرحهایی جامع در حوزه علوم داده گردیده است.
روشهای مبتنی بر نظریه اطلاعات قابل اعمال به طیف وسیعی از مسائل نوین حوزه علوم داده، شامل یادگیری ماشین، آمار، علوم کامپیوتر کاربردی، یادگیری برخط و تحقیق در عملیات است. به علاوه، نظریه اطلاعات قادر است راهکارهایی منطبق بر شهود را برای تعیین و تدوین ابزارهایی مناسب جهت حل مسائل مختلف در زمینه علوم داده به دست دهد.
اگرچه حوزه نظریه اطلاعات در ابتدا جهت یافتن پاسخهایی برای برخی مسائل بنیادین در نظریه مخابرات توسعه پیدا کرد، اما ارتباط تنگاتنگ آن با مباحث آمار و استنتاج منجر به بروز تحولی شگرف در کاربردهای مختلفی از قبیل تئوری یادگیری، یادگیری آماری و استنتاج عملی گردیده است.
روشهای مبتنی بر نظریه اطلاعات این قابلیت را دارند که شهود مناسب به همراه الگوریتمهایی کارا برای طیف متنوعی از مسائل حوزه یادگیری و استنتاج را توسعه دهند. به علاوه، سنجههای اطلاعاتی مختلفی که در این حوزه معرفی شده است، نظیر آنتروپی متقابل، آنتروپی نسبی و دیورژانسهای نظریه اطلاعاتی نقشی محوری در تحلیل و طراحی الگوریتمهای بهینه در زمینههای مختلف حوزه علوم داده از جمله آمار، تئوری یادگیری و علوم ریاضی را ایفا میکنند.
علاوه بر ارائه پاسخهایی برای مسائل مختلف حوزه علوم داده، نظریه اطلاعات نقشی محوری در یافتن پاسخ برای این سوال بنیادی که “چه چیزی غیرممکن است؟” نیز ایفا میکند. نتایج غیرممکن (کشف غیرممکن یا یافتن آنچه غیرممکن است) به کمک رهیافت نظریه اطلاعاتی برای "حدود بنیادین" قابل دستیابی هستند و به ما کمک میکنند تا اهداف غیرمعقول در حوزههای مختلف علوم داده شناسایی شده و "گلوگاه"های این حوزه (علوم داده) تبیین شوند. به علاوه، تضمینهایی برای بهینگی الگوریتمهای توسعه یافته برای مسائل نیز با این رهیافت قابل دستیابی خواهند بود.

روشهای مبتنی بر نظریه اطلاعات قابل اعمال به طیف وسیعی از مسائل نوین حوزه علوم داده، شامل یادگیری ماشین، آمار، علوم کامپیوتر کاربردی، یادگیری برخط و تحقیق در عملیات است. به علاوه، نظریه اطلاعات قادر است راهکارهایی منطبق بر شهود را برای تعیین و تدوین ابزارهایی مناسب جهت حل مسائل مختلف در زمینه علوم داده به دست دهد.
اگرچه حوزه نظریه اطلاعات در ابتدا جهت یافتن پاسخهایی برای برخی مسائل بنیادین در نظریه مخابرات توسعه پیدا کرد، اما ارتباط تنگاتنگ آن با مباحث آمار و استنتاج منجر به بروز تحولی شگرف در کاربردهای مختلفی از قبیل تئوری یادگیری، یادگیری آماری و استنتاج عملی گردیده است.
روشهای مبتنی بر نظریه اطلاعات این قابلیت را دارند که شهود مناسب به همراه الگوریتمهایی کارا برای طیف متنوعی از مسائل حوزه یادگیری و استنتاج را توسعه دهند. به علاوه، سنجههای اطلاعاتی مختلفی که در این حوزه معرفی شده است، نظیر آنتروپی متقابل، آنتروپی نسبی و دیورژانسهای نظریه اطلاعاتی نقشی محوری در تحلیل و طراحی الگوریتمهای بهینه در زمینههای مختلف حوزه علوم داده از جمله آمار، تئوری یادگیری و علوم ریاضی را ایفا میکنند.
علاوه بر ارائه پاسخهایی برای مسائل مختلف حوزه علوم داده، نظریه اطلاعات نقشی محوری در یافتن پاسخ برای این سوال بنیادی که “چه چیزی غیرممکن است؟” نیز ایفا میکند. نتایج غیرممکن (کشف غیرممکن یا یافتن آنچه غیرممکن است) به کمک رهیافت نظریه اطلاعاتی برای "حدود بنیادین" قابل دستیابی هستند و به ما کمک میکنند تا اهداف غیرمعقول در حوزههای مختلف علوم داده شناسایی شده و "گلوگاه"های این حوزه (علوم داده) تبیین شوند. به علاوه، تضمینهایی برای بهینگی الگوریتمهای توسعه یافته برای مسائل نیز با این رهیافت قابل دستیابی خواهند بود.
طبق تحلیل و پیشبینی مؤسسه McKinsey Global Institute، نیاز به متخصصین مجسمسازی داده تا سال 2026، تنها در آمریکا، به 2 تا 4 میلیون نفر خواهد رسید.
مجسمسازی داده می تواند الگوها، بینشها، ساختارها و جزئیاتی را برای کاربران به نمایش بگذارد که بدون آن هرگز متوجهشان نمیشدند. این کار، هنگام استخراج الگوها و تصمیمگیری بر اساس داده، یکی از مراحل کلیدی به شمار میرود.
ارائه داده به صورت قابل درک و مؤثر برای کاربران نیازمند تبدیل اطلاعات به نمایشهای گرافیکی جذاب و ارزشمند است. به طوری که مهمترین نکات و عمیقترین الگوها و روندهای پنهان در داده به صورت آشکار در این طرح به نمایش گذاشته شود. مصورسازی علاوه بر اینکه یک ابزار مهم برای ارتباط با مشتریان تجاری است، یکی از ابزارهای مهم دانشمندان داده نیز به شمار میرود. دانشمندان داده با استفاده از مصورسازی اصولی و حرفهای میتوانند روندهای مهم و همچنین دادههای خارج از محدوده را به سرعت تشخیص دهند و تحلیلهایی عمیقتر و مقاومتر نسبت به خطاهای بالقوه مستتر در انواع دادگان ارائه دهند.
به علاوه، برای نیازهای هر شرکت و هر کاربرد به خصوص، غالبا دادهها اصول کلی مشخصی دارند و الگوهای خاصی را دنبال میکنند. به همین دلیل مدلهای داده (data models) از اهمیت بالایی در علوم داده برخوردارند. مدلهای داده اسناد زنده و پویایی هستند که با تغییرات نیازهای مشتری تغییر میکنند. این اسناد بر اساس نیازها و الگوهای داده مشتری تدوین میشوند و براساس فیدبکها و نظرات مشتری دائما به روز میشوند.
تحلیل پیشرفته داده، بدون تدوین مدلهای داده دقیق و کاربردی، و سپس مصورسازی و نمایش بهینه آنها ناممکن است. مدلهای داده، الگوهای مناسب برای مصورسازی داده را نیز مشخص میکنند. برای ارائه راهحلهای پیشرفته و تولید مدلهای یادگیری ماشین برای مشتری، نیاز است که دائما خروجیهای هر مرحله به صورت مصور و کاملا قابل فهم به مشتری ارائه شود تا از عملکرد صحیح مدل و تطابق خروجیها با نیاز کاربر اطمینان حاصل شود. به علاوه، فهم الگوریتمهای پیچیده با استفاده از نمودارها و تصاویر گرافیکی برای مشتری بسیار آسانتر است تا اعداد و ارقام.

مجسمسازی داده می تواند الگوها، بینشها، ساختارها و جزئیاتی را برای کاربران به نمایش بگذارد که بدون آن هرگز متوجهشان نمیشدند. این کار، هنگام استخراج الگوها و تصمیمگیری بر اساس داده، یکی از مراحل کلیدی به شمار میرود.
ارائه داده به صورت قابل درک و مؤثر برای کاربران نیازمند تبدیل اطلاعات به نمایشهای گرافیکی جذاب و ارزشمند است. به طوری که مهمترین نکات و عمیقترین الگوها و روندهای پنهان در داده به صورت آشکار در این طرح به نمایش گذاشته شود. مصورسازی علاوه بر اینکه یک ابزار مهم برای ارتباط با مشتریان تجاری است، یکی از ابزارهای مهم دانشمندان داده نیز به شمار میرود. دانشمندان داده با استفاده از مصورسازی اصولی و حرفهای میتوانند روندهای مهم و همچنین دادههای خارج از محدوده را به سرعت تشخیص دهند و تحلیلهایی عمیقتر و مقاومتر نسبت به خطاهای بالقوه مستتر در انواع دادگان ارائه دهند.
به علاوه، برای نیازهای هر شرکت و هر کاربرد به خصوص، غالبا دادهها اصول کلی مشخصی دارند و الگوهای خاصی را دنبال میکنند. به همین دلیل مدلهای داده (data models) از اهمیت بالایی در علوم داده برخوردارند. مدلهای داده اسناد زنده و پویایی هستند که با تغییرات نیازهای مشتری تغییر میکنند. این اسناد بر اساس نیازها و الگوهای داده مشتری تدوین میشوند و براساس فیدبکها و نظرات مشتری دائما به روز میشوند.
تحلیل پیشرفته داده، بدون تدوین مدلهای داده دقیق و کاربردی، و سپس مصورسازی و نمایش بهینه آنها ناممکن است. مدلهای داده، الگوهای مناسب برای مصورسازی داده را نیز مشخص میکنند. برای ارائه راهحلهای پیشرفته و تولید مدلهای یادگیری ماشین برای مشتری، نیاز است که دائما خروجیهای هر مرحله به صورت مصور و کاملا قابل فهم به مشتری ارائه شود تا از عملکرد صحیح مدل و تطابق خروجیها با نیاز کاربر اطمینان حاصل شود. به علاوه، فهم الگوریتمهای پیچیده با استفاده از نمودارها و تصاویر گرافیکی برای مشتری بسیار آسانتر است تا اعداد و ارقام.
نظریه شبکه و گراف
علم شبکه به طور کلی به بررسی سیستمهای شبکهای پیچیده میپردازد. این شبکهها میتوانند کامپیوتری، مخابراتی، زیستی، اجتماعی یا اقتصادی باشند. گراف ساختاری ریاضیاتی برای مدل کردن روابط بین اشیاء است، که شامل تعدادی رأس برای خود اشیاء و یال برای ارتباطشان میباشد. هر کدام از این شبکهها تعدادی رأس دارند و ارتباط بین رأسهای آن با یال مشخص شده است. برای همین نظریه گراف را میتوان هسته اصلی علم شبکه دانست. علاوه بر نظریه گراف، روشهای آمار و احتمالی و دادهکاوی نیز بسیار در حل مسائل این حوزه استفاده میشوند. نظریه گراف شاخهای از ریاضیات گسسته است که تسلط به آن به بررسی مسائل شبکه مختلف کمک زیادی خواهد کرد.
نظریه گراف و علم شبکه دو حوزه مرتبط هستند که امروزه کابردهای زیادی در صنعت پیدا کردهاند. تحلیل شبکههای اجتماعی، شبکههای حمل و نقل، شبکههای تنظیم کننده ژن و شبکههای دانشی از نمونههای مسائل روز علم شبکه است. ماهیت شهودی و انعطاف پذیر شبکه، آن را به ابزاری قدرتمند برای توصیف سیستمهای پیچیدهی دنیای واقعی تبدیل کرده است.

نظریه گراف و علم شبکه دو حوزه مرتبط هستند که امروزه کابردهای زیادی در صنعت پیدا کردهاند. تحلیل شبکههای اجتماعی، شبکههای حمل و نقل، شبکههای تنظیم کننده ژن و شبکههای دانشی از نمونههای مسائل روز علم شبکه است. ماهیت شهودی و انعطاف پذیر شبکه، آن را به ابزاری قدرتمند برای توصیف سیستمهای پیچیدهی دنیای واقعی تبدیل کرده است.
چالشهای امنیت و حریم خصوصی نقش محوری در آیندهی "جهان متصل هوشمند" ایفا خواهند کرد.
صیانت از حریم خصوصی دادههای کاربران در شبکههای اجتماعی و دستگاههای تلفن همراه، تشخیص و مقابله با سرقت شناسه کاربران در تراکنشهای برخط و دسترسی غیرمجاز به چیپهای الکترونیکی اتومبیلهای خودران برخی از چالشهای کلیدی هستند که در زمینه سرویسهای ارائه شده مبتنی بر تکنولوژیهای علوم داده و علوم کامپیوتر به طور مستقیم کاربران را تحت تاثیر قرار میدهند.
تقابل دائمی میان حملات متخاصمانه مهاجمان فعال و توسعهدهندگان سازوکارهای دفاع در برابر این حملات امنیت و حریم خصوصی مخابره داده و شبکههای کامپیوتری را در معرض مخاطرات جدی قرار داده است.
الگوریتمهای رمزنگاری و امنیت به طور سنتی با هدف تمرکز بر ارائه راهحلهایی برای امن کردن سرویسهای بانکی و مخابرات توسعه یافتند. امروزه، با گسترش شگرف ایجاد شده در زمینههای علوم داده طیف وسیعی از کاربردها و سیستمها نیازمند تضمینهایی ویژه در زمینه امنیت و حریم خصوصی هستند. اتومبیلهای خودران، خدمات سلامت دیجیتال، کارخانهها و ساختمانهای هوشمند برخی از مثالها در این زمینهاند.
برای دستیابی به امنیت و مقاومت انتها-به-انتها برای آیندهی اتصال هوشمند، راهکارهایی میان رشتهای مورد نیاز است که تحقیقات بنیادین را با کاربردهایی عملی و خلاقانه در زمینه امنیت و حریم خصوصی برای علوم داده ترکیب نماید. به علاوه، بهرهوری مناسب از الگوریتمهای یادگیری ماشین و هوش مصنوعی کمک میکند تا عملکرد سیستمها از منظر امنیت و حریم خصوصی ارتقا یابد.
در حوزه امنیت و حریم خصوصی برای علوم داده نیازمند راهحلهایی هستیم که در عمل نیز پاسخهایی مناسب به دست دهند. برای نیل به این مقصود لازم است تا شهودی جامع از دادههای تجربی و رفتاری به دست آید. بنابراین ارائه تضمینهایی برای حفظ امنیت و حریم خصوصی در کاربردهای واقعی، به نحوی که بتوانند همگام با روند رو به رشد زیرساختهای فناوری اطلاعات حرکت نمایند، بیش از گذشته احساس میشود.
صیانت از حریم خصوصی دادههای کاربران در شبکههای اجتماعی و دستگاههای تلفن همراه، تشخیص و مقابله با سرقت شناسه کاربران در تراکنشهای برخط و دسترسی غیرمجاز به چیپهای الکترونیکی اتومبیلهای خودران برخی از چالشهای کلیدی هستند که در زمینه سرویسهای ارائه شده مبتنی بر تکنولوژیهای علوم داده و علوم کامپیوتر به طور مستقیم کاربران را تحت تاثیر قرار میدهند.
تقابل دائمی میان حملات متخاصمانه مهاجمان فعال و توسعهدهندگان سازوکارهای دفاع در برابر این حملات امنیت و حریم خصوصی مخابره داده و شبکههای کامپیوتری را در معرض مخاطرات جدی قرار داده است.
الگوریتمهای رمزنگاری و امنیت به طور سنتی با هدف تمرکز بر ارائه راهحلهایی برای امن کردن سرویسهای بانکی و مخابرات توسعه یافتند. امروزه، با گسترش شگرف ایجاد شده در زمینههای علوم داده طیف وسیعی از کاربردها و سیستمها نیازمند تضمینهایی ویژه در زمینه امنیت و حریم خصوصی هستند. اتومبیلهای خودران، خدمات سلامت دیجیتال، کارخانهها و ساختمانهای هوشمند برخی از مثالها در این زمینهاند.
برای دستیابی به امنیت و مقاومت انتها-به-انتها برای آیندهی اتصال هوشمند، راهکارهایی میان رشتهای مورد نیاز است که تحقیقات بنیادین را با کاربردهایی عملی و خلاقانه در زمینه امنیت و حریم خصوصی برای علوم داده ترکیب نماید. به علاوه، بهرهوری مناسب از الگوریتمهای یادگیری ماشین و هوش مصنوعی کمک میکند تا عملکرد سیستمها از منظر امنیت و حریم خصوصی ارتقا یابد.
در حوزه امنیت و حریم خصوصی برای علوم داده نیازمند راهحلهایی هستیم که در عمل نیز پاسخهایی مناسب به دست دهند. برای نیل به این مقصود لازم است تا شهودی جامع از دادههای تجربی و رفتاری به دست آید. بنابراین ارائه تضمینهایی برای حفظ امنیت و حریم خصوصی در کاربردهای واقعی، به نحوی که بتوانند همگام با روند رو به رشد زیرساختهای فناوری اطلاعات حرکت نمایند، بیش از گذشته احساس میشود.